Customer Churn Prediction
Date: July 2024
GitHub: BinaryClassification
Objective
Our goal was to predict potential customers who are more likely to churn using various machine learning techniques with a focus on optimizing recall and precision.
This post summarizes our journey through the stages of data exploration, feature engineering, model selection, and refinement.
Overview
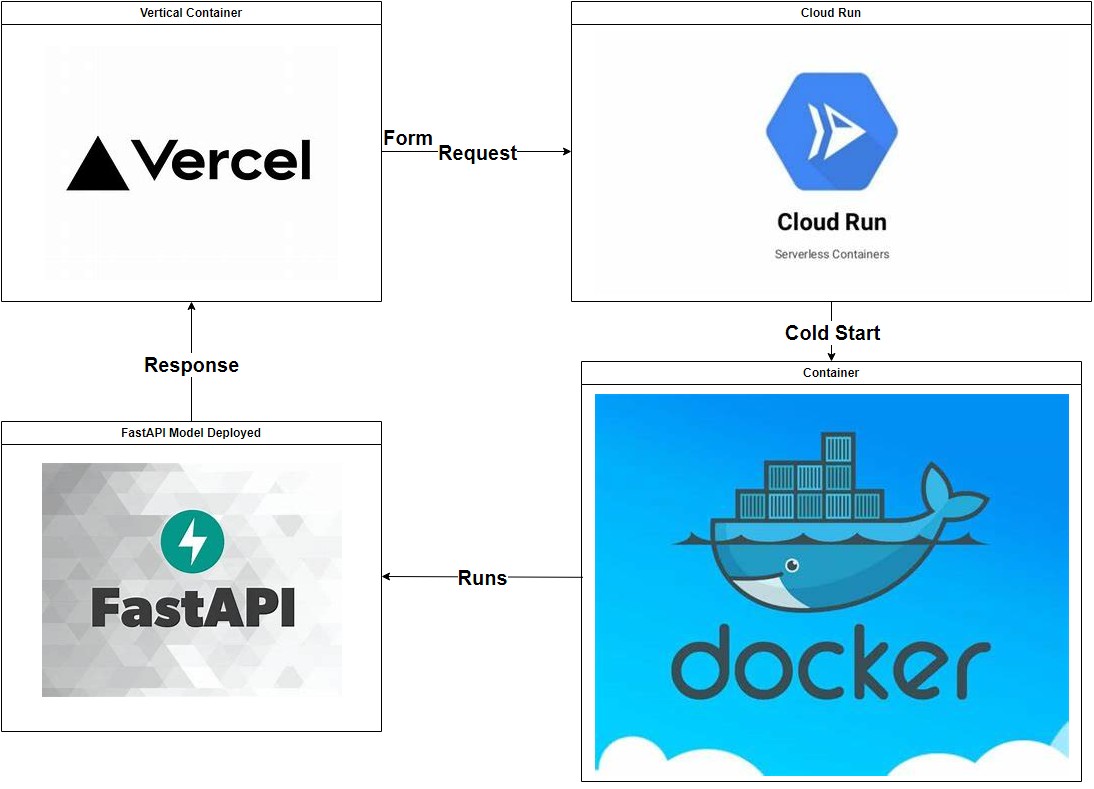
Start: Data Exploration and Preprocessing
We began by understanding the dataset’s structure and performing necessary preprocessing. This included handling missing values, encoding categorical variables, and performing initial exploratory data analysis (EDA) to identify patterns and relationships in the data.
Power BI Report
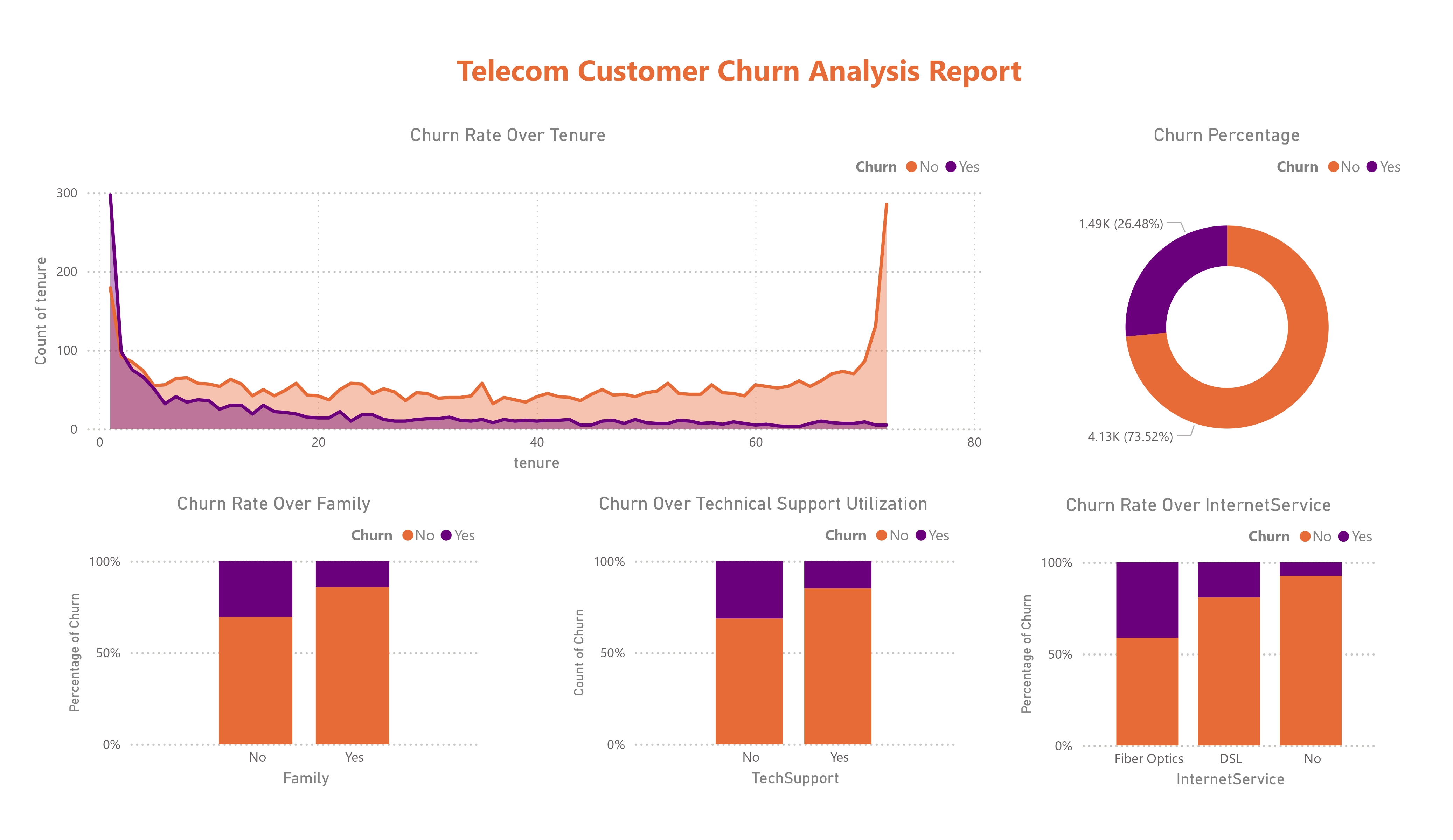
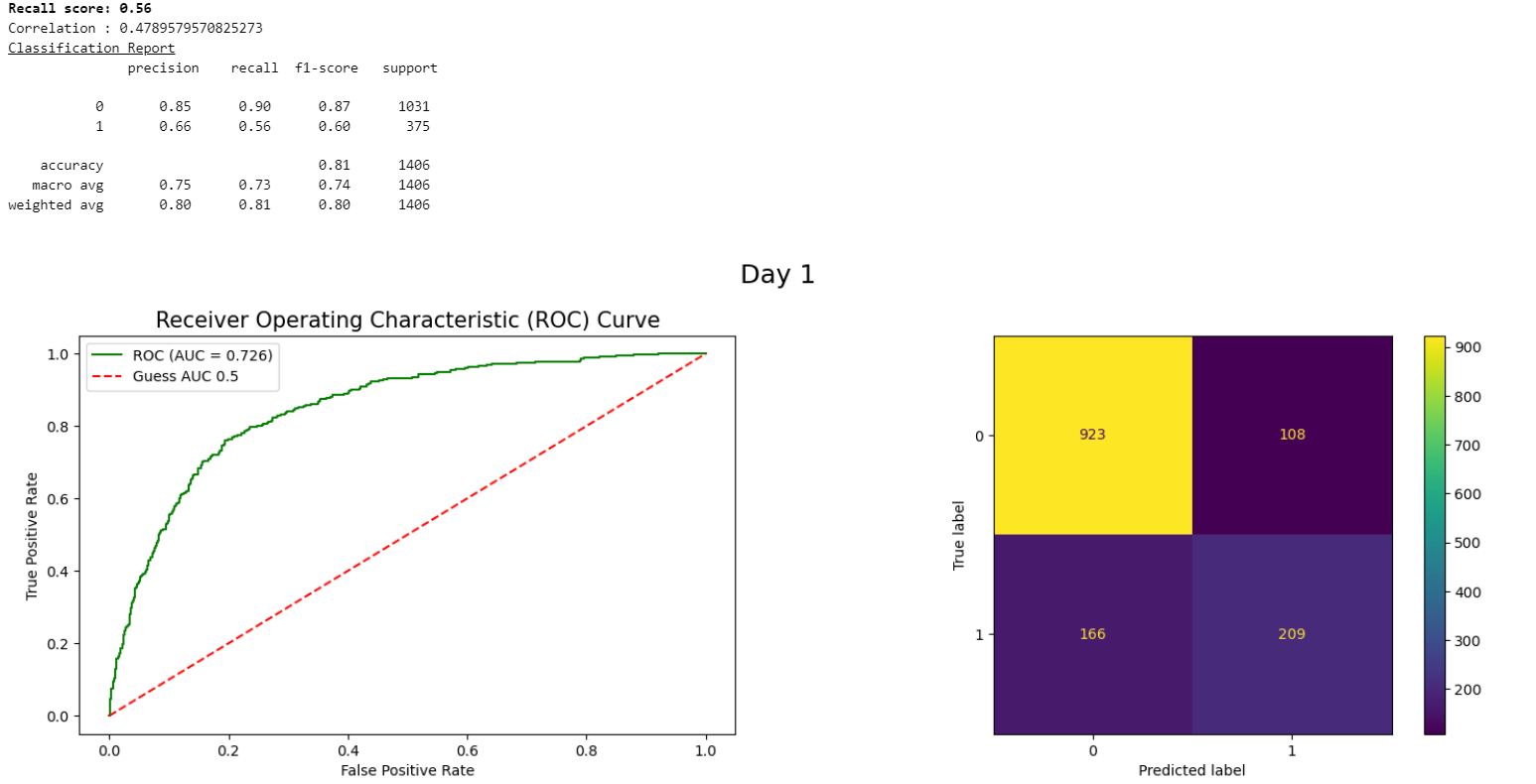
Key Insights:
- Customers with longer tenure are less likely to churn.
- About 26% of customers churned.
- Married customers are less likely to churn.
- Churn rate is higher for customers who don't have tech support.
- Churn rate is higher for customers who are using fiber optic internet service.
Technologies Used:
- Language: Python
- Visualization: Matplotlib, Seaborn
- Core Libraries: Polars, NumPy, Scikit-learn, Imbalanced-learn, CatBoost
- BI Tools: Power BI
- Development Environment: Jupyter Notebook, VS Code
- Development : Docker, Google Cloud Run
Feature Selection and Naive Modeling
To simplify the model, we dropped features with low Matthews correlation coefficient and used Variance Inflation Factor (VIF) to remove multicollinear features. We then implemented simple models using class weights to establish a baseline.
Handling Class Imbalance with SMOTE-N
Given the imbalanced nature of the churn data, we applied Synthetic Minority Over-sampling Technique for Nominal data (SMOTE-N) to balance the classes. This improved the model’s ability to predict churners effectively.
Key Insights:
- Addressing class imbalance is vital for improving model recall and precision.
Error Analysis and Model Refinement
To improve our model’s decision boundaries, we analyzed errors and introduced decision trees. This helped overcome the limitations of linear decision boundaries and led to better predictions.
Key Takeaways:
- Error analysis is essential for refining models and improving performance.
Finish: Ensemble Methods and AutoML
We implemented ensemble methods such as Random Forest and Gradient Boosting to enhance model performance. AutoML tools were also utilized to streamline model selection and hyperparameter tuning. Our final model, CatBoost, achieved excellent recall and precision.
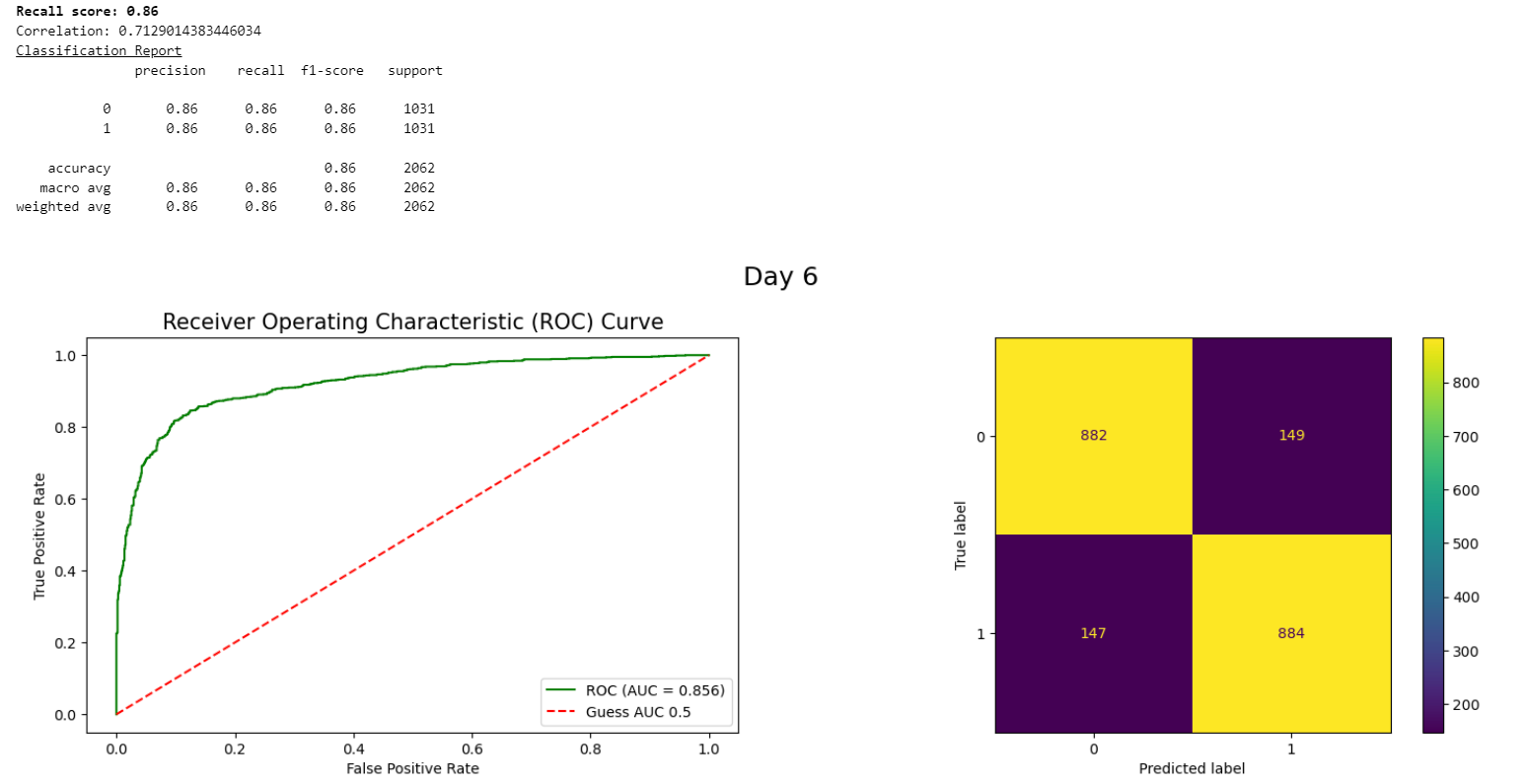
Models Used:
- Random Forest
- CatBoost
- AutoML (PyCaret, EvalML)
Key Insights:
- Ensemble methods significantly boost model performance.
Conclusion
By systematically progressing through data preprocessing, feature selection, class balancing, error analysis, and advanced techniques, we successfully built a robust model for predicting customer churn. The final model, CatBoost, achieved an impressive recall and precision of 86%, proving highly effective at identifying churners.